Decision Trees Intuition
A tree has many analogies in real life, and turns out that it has influenced a wide area of machine learning. In decision analysis, a decision tree can be used to visually and explicitly represent decisions and decision making. As the name goes, it uses a tree-like model of decisions. Though a commonly used tool in data mining for deriving a strategy to reach a particular goal, its also widely used in machine learning, which will be the main focus of this article.
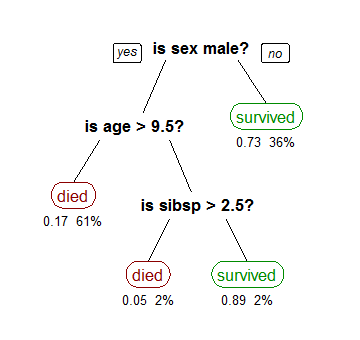
A decision tree is drawn upside down with its root at the top. In the above image, the bold text in black represents a condition/internal node, based on which the tree splits into branches/ edges. The end of the branch that doesn’t split anymore is the decision/leaf, in this case, whether the passenger died or survived, represented as red and green text respectively.
Basically the main intuition behind the decision trees are ' if-else' statements.
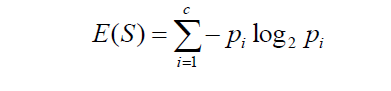
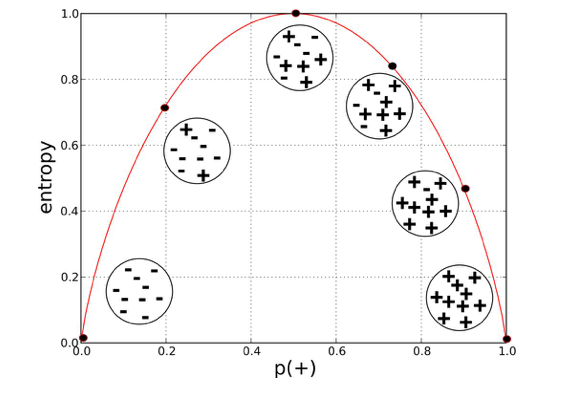
From the above fig we can conclude that if the splits contains same type of points the entropy is at the lowest, while as if the split contains equal different type of points then the entropy is at the maximum.
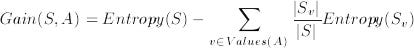
Let's learn some basic terms in decision trees which will be in use :-
- Entropy :- It is nothing but the measure of disorder. You can also think as a measure of purity as well. It helps us to find that the split that occur in our tree is good or not. Below is the formula for Entropy :-
Where ‘Pi’ is simply the frequentist probability of an element/class ‘i’ in our data. For simplicity’s sake let’s say we only have two classes , a positive class and a negative class. Therefore ‘i’ here could be either + or (-). So let's take an example in we had a total of 100 data points in our dataset with 30 belonging to the positive class and 70 belonging to the negative class then ‘P+’ would be 3/10 and ‘P-’ would be 7/10. Pretty straightforward.
Our main aim is to find the value of whose entropy is minimum, so that the split that occur is perfect.
For each child node and leaf node, entropy is calculated.
- Information gain :- It is an attribute selection method, which helps us to find the best value (i.e features in our dataset) for our parent node in a decision tree.
Our aim is to find the best attribute whose Information gain is maximum.
Information gain is calculated for the parent node only.
- Gini Impurity :- It is a technique which helps us to measure the purity of a split.
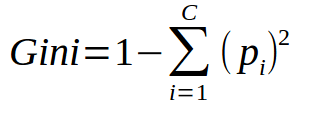
Where 'i' is the number of classes in our dataset.
Our aim is to find the best value whose Gini impurity is minimum.
For each child node and leaf node, gini impurity is calculated.
So, the question arises is that why should we introduced gini impurity if we already have entropy. They both helps us to find the purity of a split.
The difference is that in entropy formula the ' log ' function is included, but in gini impurity the formula is simple(without any log function). So, the time complexity in gini impurity is less than that in entropy.
There are basically two type of decision trees :-
Regression trees - A regression tree is used when the dependent variable is continuous. The value obtained by leaf nodes in the training data is the mean response of observation falling in that region. Thus, if an unseen data observation falls in that region, its prediction is made with the mean value. This means that even if the dependent variable in training data was continuous, it will only take discrete values in the test set. A regression tree follows a top-down greedy approach.
Classification trees - A classification tree is used when the dependent variable is categorical. The value obtained by leaf nodes in the training data is the mode response of observation falling in that region It follows a top-down greedy approach.
Together they are called as CART(classification and regression tree)
The Biggest disadvantage of the decision trees is Overfitting. It means that in our model the error rate of our training data is low whereas the error in test data is high. It is also known as Low Bias and High Variance. This problem occur when the split of the trees goes to its depth.
' Pruning ' a solution to our overfitting problem.
Comments
Post a Comment